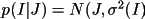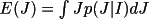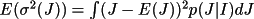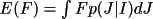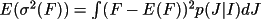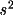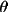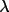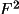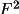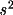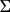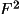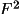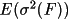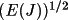BAYEST
: Bayesian estimates of |I| and |F|
Author: Nick Spadaccini,
Computer Science Department, University of Western Australia,
Nedlands, WA 6907, Australia
BAYEST determines a posterior intensity and/or
structure factor modulus and the associated standard
deviations. The program is useful in the treatment of weak
or negative intensities. The calculation is based on the
work of French and Wilson (1978), and the user should refer
to the original paper for details of the method.
Intensity measurements which are negative are
generally either excluded from the data set or are reset to
zero. Both these practices result in biased determinations
of the structure. This bias may be overcome by including
all reflections in a refinement based on
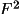 . However, for
refinements based on F(rel) it is essential to obtain the
best possible estimates to the structure factor modulus and
its standard deviation.
. However, for
refinements based on F(rel) it is essential to obtain the
best possible estimates to the structure factor modulus and
its standard deviation.
A more adequate treatment of negative or weak
intensities is required. Setting the structure factor to
zero ignores the information present in the observation of
a negative intensity (i.e. it is weak). Assuming the
intensity distribution of data follows the Wilson
distribution, and that the true intensity is constrained to
be non-negative, a posterior estimate of I or F(rel) and
their standard deviations can be made.
BAYEST is a two pass operation. The first pass
determines the data set distribution and the second pass
applies the Bayesian corrections. Items which MUST be
present on the bdf are the maximum and minimum values of s,
s for each reflection, and either of intensity and Lp, or
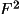 . No expansion to the
bdf is made. The items input are also output, though the
user has the option to apply the correction as
desired.
. No expansion to the
bdf is made. The items input are also output, though the
user has the option to apply the correction as
desired.
In this run the data is divided into 35 groups and
the correction is applied to F(rel) only leaving the other
items uncorrected. The printing is suppressed. Note that
F(rel) and
 (F) must be
present in the input bdf. BAYEST does not expand the bdf by
generating F(rel) from I or
(F) must be
present in the input bdf. BAYEST does not expand the bdf by
generating F(rel) from I or
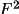 . That is left to
ADDREF.
. That is left to
ADDREF.